Choice Models
Contents
Choice Models¶
import larch.numba as lx
In this guide, we’ll take a look at building a discrete choice model using Larch. We assume you have a decent grasp of the fundamentals of choice modeling – if not, we suggest reading the Discrete Choice Modeling section of the Python for Transportation Modeling course.
Some addition advanced or detailed topics are broken out into seperate guides:
The examples below work with the tiny dataset introduced in the Data Fundamentals section.
# HIDDEN
df_ca = pd.read_csv("example-data/tiny_idca.csv")
cats = df_ca['altid'].astype(pd.CategoricalDtype(['Car', 'Bus', 'Walk'])).cat
df_ca['altnum'] = cats.codes + 1
df_ca = df_ca.set_index(['caseid', 'altnum'])
data = lx.Dataset.construct.from_idca(df_ca.sort_index(), fill_missing=0)
data = data.drop_vars("_avail_")
data['ChosenCode'] = (data['Chosen'] * data['Chosen'].altnum).sum('altnum')
data.coords['alt_names'] = lx.DataArray(cats.categories, dims=('altnum'), coords={'altnum': data.altnum})
alts = dict(zip(data['altnum'].values, data['alt_names'].values))
for i, k in alts.items():
data[f'{k}Time'] = data['Time'].sel(altnum=i)
data
<xarray.Dataset>
Dimensions: (caseid: 4, altnum: 3)
Coordinates:
* caseid (caseid) int64 1 2 3 4
* altnum (altnum) int64 1 2 3
alt_names (altnum) object 'Car' 'Bus' 'Walk'
Data variables:
altid (caseid, altnum) object 'Car' 'Bus' 'Walk' ... 'Bus' 'Walk'
Income (caseid) int64 30000 30000 40000 50000
Time (caseid, altnum) int64 30 40 20 25 35 0 40 50 30 15 20 10
Cost (caseid, altnum) int64 150 100 0 125 100 0 125 75 0 225 150 0
Chosen (caseid, altnum) int64 1 0 0 0 1 0 0 0 1 0 0 1
ChosenCode (caseid) int64 1 2 3 3
CarTime (caseid) int64 30 25 40 15
BusTime (caseid) int64 40 35 50 20
WalkTime (caseid) int64 20 0 30 10
Attributes:
_caseid_: caseid
_altid_: altnumThe basic structure of a choice model in Larch is contained in the
Model object.
m = lx.Model(data)
Choices¶
The dependent variable for a discrete choice model is an array that describes the choices. In Larch, there are three different ways to indicate choices, by assigning to different attributes:
m.choice_ca_var
: The choices are given by indicator values (typically but not
neccessarily dummy variables) in an idca variable.
m.choice_co_code
: The choices are given by altid values in an idco variable.
These choice codes are then converted to binary indicators
by Larch.
m.choice_co_vars
: The choices are given by indicator values (typically but not
neccessarily dummy variables) in multiple idco variables,
one for each alternative.
Given the dataset (which has all these formats defined), all the following choice definitions result in the same choice representation:
m.choice_co_code = 'ChosenCode'
m.choice_co_vars = {
1: 'ChosenCode == 1',
2: 'ChosenCode == 2',
3: 'ChosenCode == 3',
}
m.choice_ca_var = 'Chosen'
After setting the choice definition, the loaded or computed choice array
should be available as the 'ch' DataArray in the model’s
dataset.
m.dataset['ch']
<xarray.DataArray 'ch' (caseid: 4, altnum: 3)>
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[0, 0, 1]])
Coordinates:
* caseid (caseid) int64 1 2 3 4
* altnum (altnum) int64 1 2 3
alt_names (altnum) object 'Car' 'Bus' 'Walk'Availability¶
In addition to the choices, we can also define an array that describes the availability of the various alternatives. Unlike the choices, for the availability factors we expect that we’ll need to toggle the availability on or off for potentially every alternative in each case, so there’s only two ways to define availability, by assigning to attributes:
m.availability_ca_var
: The availability of alternatives is given by binary values
(booleans, or equivalent integers) in an idca variable.
m.availability_co_vars
: The availability of alternatives is given by binary values
(booleans, or equivalent integers) in multiple idco variables,
one for each alternative.
Given the dataset, both of the following availability definitions result in the same availability representation:
m.availability_ca_var = "Time > 0"
m.availability_co_vars = {
1: True,
2: 'BusTime > 0',
3: 'WalkTime > 0',
}
After setting the availability definition, the loaded or computed availability array
should be available as the 'av' DataArray in the model’s
dataset.
m.dataset['av']
<xarray.DataArray 'av' (caseid: 4, altnum: 3)>
array([[1, 1, 1],
[1, 1, 0],
[1, 1, 1],
[1, 1, 1]], dtype=int8)
Coordinates:
* caseid (caseid) int64 1 2 3 4
* altnum (altnum) int64 1 2 3
alt_names (altnum) object 'Car' 'Bus' 'Walk'Utility Functions¶
Choice models in Larch rely on utility expressions that are
linear-in-parameters functions, which combine
parameters P and data
X. You can attach these function
expressions to the model in two ways:
m.utility_ca
: A linear function containing generic expressions
that are evaluated against the idca portion of the dataset.
These expression can technically also reference idco variables,
but to define a well-specified choice model with identifiable
parameters, each data term will need at least one idca
component.
m.utility_co
: A mapping of alternative-specific expressions that are evaluated
against only the idco portion of the dataset. Each key gives
an alternative id, and the values are linear functions.
These two utility function definitions are not mutually exclusive, and you can mix both types of functions in the same model.
from larch import P, X
m.utility_ca = P.Time * X.Time + P.Cost * X.Cost
m.utility_co = {
1: P.Income_Car * X.Income / 1000,
2: P.Income_Bus * X.Income / 1000,
}
The computed values for the utility function can be accessed using
the utility method, which also permits
the user to set new values for various model parameters.
m.utility(
{'Time': -0.01, 'Cost': -0.02, 'Income_Car': 0.1},
return_format='dataarray',
)
<xarray.DataArray (caseid: 4, nodeid: 4)>
array([[-0.3 , -2.4 , -0.2 , 0.50093705],
[ 0.25 , -2.35 , -inf, 0.32164469],
[ 1.1 , -2. , -0.3 , 1.3559175 ],
[ 0.35 , -3.2 , -0.1 , 0.86063728]])
Coordinates:
* caseid (caseid) int64 1 2 3 4
* nodeid (nodeid) int64 1 2 3 0
node_name (nodeid) <U6 'Car' 'Bus' 'Walk' '_root_'Data Preparation¶
Larch works with two “tiers” of data:
m.datatree
: A DataTree that holds the raw data used for the model. This can
consist of just a single Dataset, (which is automatically converted
into a one-node tree when you assign it to this attribute) or multiple
related datasets linked together using the sharrow library.
m.dataset
: The assembled arrays actually used in calculation, stored
as a Dataset that has variables for various required data elements
and dimensions structured to support the model design.
The dataset is wiped out when any aspect of the model structure is
changed, and rebuilt as needed for computation. For
particular applications that require specialized
optimization, the dataset can be provided exogenously after the
model stucture is finalized, but generally
it will be convenient for users to let Larch build the dataset
automatically from a datatree.
m.datatree
<larch.dataset.DataTree>
datasets:
- main
relationships: none
m.dataset
<xarray.Dataset>
Dimensions: (caseid: 4, altnum: 3, var_co: 1, var_ca: 2)
Coordinates:
* caseid (caseid) int64 1 2 3 4
* altnum (altnum) int64 1 2 3
alt_names (altnum) object 'Car' 'Bus' 'Walk'
* var_co (var_co) <U6 'Income'
* var_ca (var_ca) <U4 'Cost' 'Time'
Data variables:
co (caseid, var_co) float64 3e+04 3e+04 4e+04 5e+04
ca (caseid, altnum, var_ca) float64 150.0 30.0 100.0 ... 0.0 10.0
ch (caseid, altnum) int64 1 0 0 0 1 0 0 0 1 0 0 1
av (caseid, altnum) int8 1 1 1 1 1 0 1 1 1 1 1 1
Attributes:
_caseid_: caseid
_altid_: altnumNesting Structures¶
By default, a model in Larch is assumed to be a simple multinomial
logit model, unless a nesting structure is defined. That structure
is defined in a model’s graph.
m.graph
Adding a nest can be accomplished the the new_node method,
which allows you to give a nesting node’s child codes, a name, and attach a logsum parameter.
z = m.graph.new_node(parameter='Mu_Motorized', children=[1,2], name='Motorized')
m.graph
The return value of new_node
is the code number of the new nest. This is assigned automatically so
as to not overlap with any other alternatives or nests. We can use this
to develop multi-level nesting structures, by putting that new code
number as the child for yet another new nest.
m.graph.new_node(parameter='Mu_Omni', children=[z, 3], name='Omni')
m.graph
Nothing in Larch prevents you from overloading the nesting structure with
degenerate nests, as shown above. You may have difficult with estimating
parameters if you are not careful with such complex structures. If you
need to remove_node, you
can do so by giving its code–but you’ll likely find you’ll be much better off
just fixing your code and starting over, as node removal can have some odd
side effects for complex structures.
m.graph.remove_node(5)
m.graph
Parameter Estimation¶
Larch can automatically find all the model parameters contained in the model specification, so we don’t need to address them separately unless we want to modify any defaults.
We can review the parameters Larch has found, as well as the current values
set for them, in the parameter frame, or pf.
m.pf
| value | initvalue | nullvalue | minimum | maximum | holdfast | note | |
|---|---|---|---|---|---|---|---|
| Cost | -0.02 | 0.0 | 0.0 | -inf | inf | 0 | |
| Income_Bus | 0.00 | 0.0 | 0.0 | -inf | inf | 0 | |
| Income_Car | 0.10 | 0.0 | 0.0 | -inf | inf | 0 | |
| Mu_Motorized | 1.00 | 1.0 | 1.0 | 0.001 | 1.0 | 0 | |
| Time | -0.01 | 0.0 | 0.0 | -inf | inf | 0 |
If we want to set certain parameters to be constrained to be certain values,
that can be accomplished with the lock_value method.
Because our sample data has so few observations, it won’t be possible to estimate
values for all four parameters, so we can assert values for two of them.
m.lock_value('Time', -0.01)
m.lock_value('Cost', -0.02)
m.pf
| value | initvalue | nullvalue | minimum | maximum | holdfast | note | |
|---|---|---|---|---|---|---|---|
| Cost | -0.02 | -0.02 | -0.02 | -0.020 | -0.02 | 1 | |
| Income_Bus | 0.00 | 0.00 | 0.00 | -inf | inf | 0 | |
| Income_Car | 0.10 | 0.00 | 0.00 | -inf | inf | 0 | |
| Mu_Motorized | 1.00 | 1.00 | 1.00 | 0.001 | 1.00 | 0 | |
| Time | -0.01 | -0.01 | -0.01 | -0.010 | -0.01 | 1 |
The default infinite bounds on the remaining parameters can be problematic
for some optimization algorithms, so it’s usually good practice to set large
but finite limits for those values. The set_cap method
can do just that, setting a minimum and maximum value for all the parameters
that otherwise have bounds outside the cap.
m.set_cap(100)
m.pf
| value | initvalue | nullvalue | minimum | maximum | holdfast | note | |
|---|---|---|---|---|---|---|---|
| Cost | -0.02 | -0.02 | -0.02 | -0.020 | -0.02 | 1 | |
| Income_Bus | 0.00 | 0.00 | 0.00 | -100.000 | 100.00 | 0 | |
| Income_Car | 0.10 | 0.00 | 0.00 | -100.000 | 100.00 | 0 | |
| Mu_Motorized | 1.00 | 1.00 | 1.00 | 0.001 | 1.00 | 0 | |
| Time | -0.01 | -0.01 | -0.01 | -0.010 | -0.01 | 1 |
To actually develop maximum likelihood estimates for the remaining
unconstrained parameters, use the
maximize_loglike method.
m.maximize_loglike()
Iteration 006 [Optimization terminated successfully]
Best LL = -3.7482392442904424
| value | initvalue | nullvalue | minimum | maximum | holdfast | note | best | |
|---|---|---|---|---|---|---|---|---|
| Cost | -0.020000 | -0.02 | -0.02 | -0.020 | -0.02 | 1 | -0.020000 | |
| Income_Bus | 0.015746 | 0.00 | 0.00 | -100.000 | 100.00 | 0 | 0.015746 | |
| Income_Car | 0.036117 | 0.00 | 0.00 | -100.000 | 100.00 | 0 | 0.036117 | |
| Mu_Motorized | 1.000000 | 1.00 | 1.00 | 0.001 | 1.00 | 0 | 1.000000 | |
| Time | -0.010000 | -0.01 | -0.01 | -0.010 | -0.01 | 1 | -0.010000 |
| key | value | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x |
| ||||||||||||
| loglike | -3.7482392442904424 | ||||||||||||
| d_loglike |
| ||||||||||||
| nit | 6 | ||||||||||||
| nfev | 15 | ||||||||||||
| njev | 6 | ||||||||||||
| status | 0 | ||||||||||||
| message | 'Optimization terminated successfully' | ||||||||||||
| success | True | ||||||||||||
| elapsed_time | 0:00:00.035555 | ||||||||||||
| method | 'slsqp' | ||||||||||||
| n_cases | 4 | ||||||||||||
| iteration_number | 6 | ||||||||||||
| logloss | 0.9370598110726106 |
In a Jupyter notebook, this method displays a live-updating view of the progress of the optmization algorithm, so that the analyst can interrupt if something looks wrong.
The maximize_loglike method does
not include the calculation of parameter covariance matrixes, standard
errors, or t-statistics. For large models, this can be a computationally
expensive process, and it is often but not always necessary. Those
computatations are made in the
calculate_parameter_covariance
method instead. Once completed, things like t-statistics and standard
errors are available in the parameter frame.
m.calculate_parameter_covariance()
m.pf
| value | initvalue | nullvalue | minimum | maximum | holdfast | note | best | std_err | t_stat | robust_std_err | robust_t_stat | unconstrained_std_err | unconstrained_t_stat | constrained | likelihood_ratio | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cost | -0.020000 | -0.02 | -0.02 | -0.020 | -0.02 | 1 | -0.020000 | NaN | NaN | 0.000000 | NaN | 0.000000 | NaN | fixed value | NaN | |
| Income_Bus | 0.015746 | 0.00 | 0.00 | -100.000 | 100.00 | 0 | 0.015746 | 0.039390 | 0.399756 | 0.023284 | 0.676282 | 0.044789 | 0.351566 | NaN | ||
| Income_Car | 0.036117 | 0.00 | 0.00 | -100.000 | 100.00 | 0 | 0.036117 | 0.042282 | 0.854199 | 0.048024 | 0.752071 | 0.048065 | 0.751424 | NaN | ||
| Mu_Motorized | 1.000000 | 1.00 | 1.00 | 0.001 | 1.00 | 0 | 1.000000 | 0.000000 | NaN | 0.521577 | 0.000000 | 1.296339 | 0.000000 | Mu_Motorized ≤ 1.0 | 0.0 | |
| Time | -0.010000 | -0.01 | -0.01 | -0.010 | -0.01 | 1 | -0.010000 | NaN | NaN | 0.000000 | NaN | 0.000000 | NaN | fixed value | NaN |
Reporting¶
Larch includes a variety of pre-packaged and a la carte reporting options.
Commonly used report tables are available directly in a Jupyter notebook through a selection of reporting functions.
m.parameter_summary()
| Value | Std Err | t Stat | Signif | Like Ratio | Null Value | Constrained | |
|---|---|---|---|---|---|---|---|
| Cost | -0.0200 | NA | NA | NA | -0.02 | fixed value | |
| Income_Bus | 0.0157 | 0.0394 | 0.40 | NA | 0.00 | ||
| Income_Car | 0.0361 | 0.0423 | 0.85 | NA | 0.00 | ||
| Mu_Motorized | 1.00 | 0.00 | NA | [] | 0.00 | 1.00 | Mu_Motorized ≤ 1.0 |
| Time | -0.0100 | NA | NA | NA | -0.01 | fixed value |
m.estimation_statistics()
| Statistic | Aggregate | Per Case |
|---|---|---|
| Number of Cases | 4 | |
| Log Likelihood at Convergence | -3.75 | -0.94 |
| Log Likelihood at Null Parameters | -4.04 | -1.01 |
| Rho Squared w.r.t. Null Parameters | 0.072 | |
m.most_recent_estimation_result
| key | value | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x |
| ||||||||||||
| loglike | -3.7482392442904424 | ||||||||||||
| d_loglike |
| ||||||||||||
| nit | 6 | ||||||||||||
| nfev | 15 | ||||||||||||
| njev | 6 | ||||||||||||
| status | 0 | ||||||||||||
| message | 'Optimization terminated successfully' | ||||||||||||
| success | True | ||||||||||||
| elapsed_time | 0:00:00.035555 | ||||||||||||
| method | 'slsqp' | ||||||||||||
| n_cases | 4 | ||||||||||||
| iteration_number | 6 | ||||||||||||
| logloss | 0.9370598110726106 |
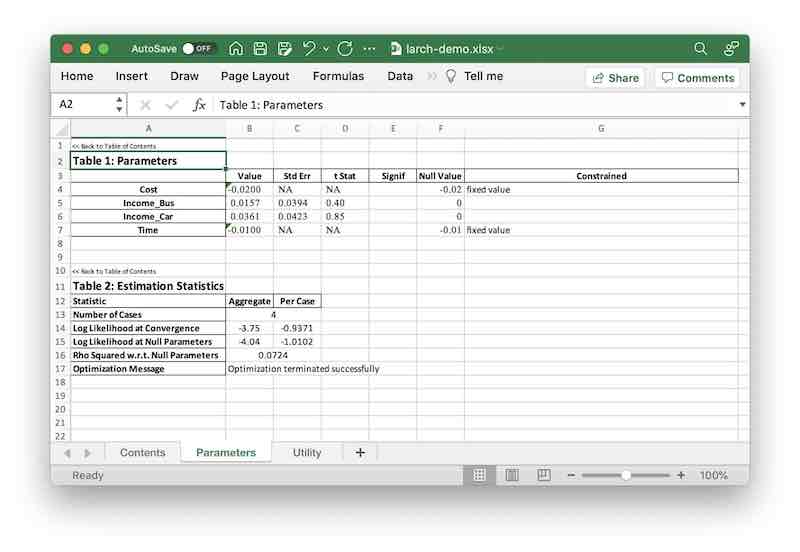
To save a model report to an Excel file, use the to_xlsx method.
m.to_xlsx("/tmp/larch-demo.xlsx")
/home/runner/work/larch/larch/larch/larch/util/excel.py:523: FutureWarning: Use of **kwargs is deprecated, use engine_kwargs instead.
xl = ExcelWriter(filename, engine='xlsxwriter_larch', model=model, **kwargs)
<larch.util.excel.ExcelWriter at 0x7f260dbc0cd0>